This article explores the concept of tooling for frontend development on the web. You will learn why we need frontend tooling, the various stages of evolution it has gone through, and the new developments that will shape the frontend build tools of the future. To follow along with this article, a general understanding of modern frontend development on the web is necessary.
Frontend build tooling is crucial to the workflow of the modern frontend developer for a host of reasons classified under improved developer and user experiences. From the developer’s perspective, frontend tooling gives us: the ability to author modules, a dev server for local development, Hot Module Replacement (HMR) for a shorter feedback loop in development mode, the ability to target legacy browsers with polyfills, processing a host of filetypes apart from JavaScript, the list goes on.
As a result, users can enjoy more capable and feature-rich applications that remain performant through techniques like code-splitting, caching, prefetching, and other resource optimization techniques — with some applications that are even able to work offline.
Frontend tooling gives us so much today that it is hard to imagine that there was a time when it was not even needed at all. A trip down memory lane could help us understand how we got here.
The Past
Before frontend applications became as complex as they are today, all JavaScript was used for was to add basic interactivity to otherwise simple HTML documents — similar to the way Adobe’s Flash was used.
There were no complex “JavaScript-heavy” applications, so, no need for any tooling to make authoring and shipping JavaScript better, but that would not remain the case.
As time went on and we started to create more involved user experiences on the web, we shifted from more static web pages to highly dynamic web applications serving user-specific data. These applications required more JavaScript than their traditional counterparts, and the limits of working with JavaScript became a lot more apparent.
There are two major ways to load JavaScript in the browser. One is with a script tag referencing a JavaScript file, and the other is to write your JavaScript directly in the HTML inside script tags.
This limitation on loading JavaScript becomes a bottleneck when you have lots of JavaScript to load. There are browser limitations to loading many JavaScript files concurrently and maintainability issues with having one huge JavaScript file (like file size, scoping issues, namespace collision, and so on).
We came up with solutions like Immediately Invoked Function Expressions (IIFEs) to help with encapsulation and some of the scoping issues after which, we gained the ability to write our JavaScript in many different files. Then, we needed a way for these many files to be combined into one file to be served in the browser
The present
Being able to split our JavaScript into different files with IIFEs, it seemed like all we needed was a way to concatenate these files and ship a single file to the browser. This need saw the rise of tools like Gulp, Grunt, Brocolli, and so forth. However, we soon realized that our thinking might have been a little too simplistic.
As our applications got even more complex, matters like lack of dead code elimination, full rebuilds for small changes, and other performance issues made us realize that we needed something more than just concatenation. That gave rise to the more modern bundlers like Webpack, Parcel, and others.
With the pace of advancement in the frontend space not slowing down, we have started to observe gaps and issues with the modern build tools.
Some of the major limitations include:
- Complex setup and configuration of some of these existing bundlers;
- Increase in build times as applications get larger;
- Suboptimal performance in development mode.
The rate at which things change in the JavaScript ecosystem is often fatiguing, but the upside is that the community quickly identifies problems and gets to work on potential solutions. With our sights set on improving the performance of frontend tooling, a new generation of build tools is being developed.
The Future
The limitations of the mainstream build tools of the day have led to several attempts to reimagine what a frontend build tool should be and do, and there are quite a few new build tools in the wild today.
Closer inspection will reveal that these new tools seem to be taking two major approaches to solving the problem (not necessarily mutually exclusive): a change in paradigm and a change in platform — both powered by new advancements in the web development ecosystem.
A Replatform
Frontend build tools have traditionally been built with JavaScript and, more recently, Typescript. This made sense, as JavaScript is the language of the web, and authoring build tools for the web in the same language makes it easier for more people to contribute to the effort and build a community around these tools. Still, there are inherent problems with this approach.
As a high-level language, JavaScript cannot reach native levels of performance. This means that tools built on top of this platform have a cap on how performant they can be. So, to break out of this limitation, newer build tools are being built on lower-level, inherently more performant languages like Rust.
Languages like Rust and Go have become popular options for authoring the next generation of build tools with a strong emphasis on performance. Rust, in particular, is popular not only for its performance but also for its impressive developer experience — voted the “most-loved” programming language six years in a row in the Stack Overflow Developer Survey.
In speaking about the decision to build Rome (the build tool and not the city) with Rust, Jamie Kyle says:
“Many others have communicated the performance, memory, and safety benefits of Rust before us — let’s just say everyone who has ever said Rust is good is correct. However, our biggest concern was our own productivity. [...] After some prototyping, however, we quickly realized we might actually be more productive in Rust”
— Jamie Kyle in Rome Will Be Written In Rust
The project SWC is at the forefront of this idea of using Rust for frontend build tools. It is now powering projects like Next.js’s new compiler, Deno, Parcel, and others — with a performance that is many orders of magnitude above other existing build tools.
Projects like SWC prove that with a change of the underlying platform, the performance of build tools can be significantly improved.
A paradigm shift
The way a typical frontend build pipeline works today is you author JavaScript modules in many different files, run a command, the build tool picks up these modules, bundles them into a single module, converts them to a format understood by browsers, and serves that file in the browser.
To improve the performance in development mode, a lot of the optimizations that would take more time to complete are left out and are, instead run when we are bundling our production application. This ensures that it takes as little time as possible to spin up a dev server, run our application in development mode and get productive.
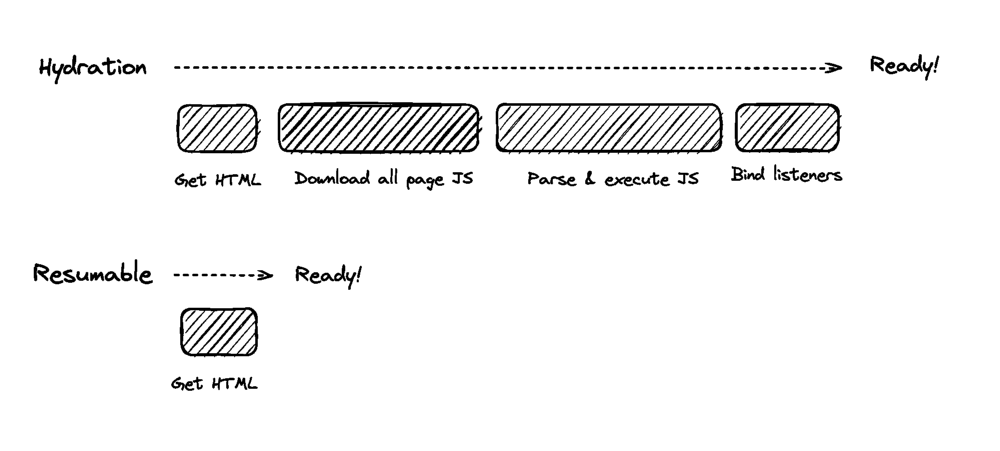
The bundling process still takes quite some time, though and as a project grows, build times (even in development) only get longer and longer. Wouldn’t it be great if we could somehow skip bundling altogether while still being able to write modules as usual and have the browser understand how to work with them? A new set of build tools is taking this approach, known as Unbundled Development.
Unbundled development is great. It solves a major issue with existing build tools: they often need to rebuild entire sections of your application for even trivial code changes, and build times get longer as the application grows. We lose the rapid feedback — essential for a pleasant development experience.
One might wonder, if unbundled development is so great, why isn’t it the norm today? There are two major reasons why unbundled development is only starting to gain traction: browser compatibility for cutting edge features and processing node module imports.
1. Browser compatibility for cutting edge features
Unbundled
Development is powered by ES Modules (ESM), which brings a standardized
module system to JavaScript — supported natively across multiple
runtimes, including the browser. With this new capability, we can mark
our script tags as modules and can consequently use the import and export keywords that we are all familiar with;
ES modules have been around for quite some time. Still, we are only able to start taking advantage of it for things like unbundled development, mostly because of how long its standardization took across all the players in the web ecosystem.
In her article about ES Modules, on Mozilla Hacks, Lin Clark says:
“ES modules bring an official, standardized module system to JavaScript. It took a while to get here, though — nearly 10 years of standardization work.”
— Lin Clark in ES Modules: A Cartoon Deep-Dive
The issue of browser support or lack thereof has plagued frontend development for a long time. This is why we have vendor prefixing our CSS, sometimes the reason for polyfills, why we spend time ensuring cross-platform support for our web applications, and why it sometimes takes quite some time before we can take advantage of the latest and greatest web features in our day to day work.
Try to visit a StackBlitz project using Safari, and you will be greeted with the following screen communicating the lack of support for WebContainers in non-Chromium-based browsers.
The pace of feature adoption is not the same across browser providers, and there are often variations in how different vendors implement certain features. However, the future looks bright with initiatives like Interop 2022.
2. Processing node module imports
Most, if not all, frontend applications we write today depend on external libraries from NPM. For a typical react application, We would import react at the top of our component files like so:
Trying
to load this directly in the browser, as we would need to do for
unbundled development, will lead to two issues. First, the browser does
not know how to resolve the path to find react and
secondly, the react library is published as a Common JS (CJS) module —
which cannot run natively in the browser without some pre-processing.
The latter is the bigger issue here, as it is possible, and even trivial, to simply replace our node module imports with relative paths to specific files. Still, the fact that most NPM packages are written in a module format more suitable for Node JS than the browser requires that our NPM dependencies are treated specially to facilitate unbundled development.
Snowpack, in particular, handles this by processing application dependencies into separate Javascript files that can then be used directly in the browser. More on how Snowpack does this can be found here.
With ES Modules now being mainstream in most modern browsers, and clever workarounds for NPM dependencies, build tools like Vite and Snowpack can offer the option of unbundled development with drastically improved performance, snappy builds, besides super fast HMR.
Final Thoughts
Frontend development has come a long way, and our needs are constantly evolving and increasing in complexity. Build tools are an essential part of how we build frontend applications, and existing tools are falling short of the mark sparking the development of new tools that reimagine how build tools should be designed.
With a huge focus on performance, ease of use, and less complex configuration, the next generation of build tools are poised to power ambitious frontend applications for some time to come.
Are you excited about the recent developments in this space? Let me know in the comments what you think about the upcoming innovations and the current landscape.