With
one billion people aged 60 or older worldwide, inclusivity is more
important than ever. Learn how to create digital experiences that
empower independence and competence for older adults while enhancing
usability for all. An upcoming part of Smart Interface Design Patterns.
Today, one billion people are 60 years or older.
That’s 12% of the entire world population, and the age group is growing
faster than any other group. Yet, online, the needs of older adults are
often overlooked or omitted. So what do we need to consider to make our
designs more inclusive for older adults? Well, let’s take a closer look.
When
designing for older adults, we shouldn’t make our design decisions
based on stereotypes or assumptions that are often not true at all.
Don’t assume that older adults struggle to use digital. Most users are
healthy, active, and have a solid income.
They might use the web differently than younger users, but that doesn’t mean we need to design a “barebones” version for them. What we need is a reliable, inclusive digital experience that helps everyone feel independent and competent.
Good accessibility is good for everyone. To make it happen, we need to bring older adults into our design process and find out what their needs are. This doesn’t only benefit the older audience but improves the overall UX — for everyone.
When designing for older users, keep in mind that there are significant differences in age groups 60–65, 65–70, 70–75, and so on, so explore design decisions for each group individually.
Older adults often read and analyze every word (so-called Stroop effect),
so give them enough time to achieve a task, as well as control the
process. So avoid disappearing messages so that users can close them
themselves when they are ready or present only 1 question at a time in a
form.
Place error messages above the input and add an error summary to highlight errors prominently. (An example from Gov.uk) (Large preview)
Older adults also often struggle with precise movements,
so avoid long, fine drag gestures and precision. If a user performs an
action, they didn’t mean to and runs into an error, be sure your error
messages are helpful and forgiving, as older adults often view error
messages as a personal failure.
As Peter Sylwester has suggested,
sensory reaction times peak at about the age of 24 and then degrade
slowly as we age. Most humans maintain fine motor skills and decent
reaction times well into old age. Therefore, error messages and small
updates and prompts should almost always be a consideration. One good
way to facilitate reaction time is to keep errors and prompts close to
the center of attention.
As always, when it comes to accessibility, watch out for contrast.
Particularly, shades of blue/purple and yellow/green are often
difficult to distinguish. When using icons, it is also a good idea to
add descriptive labels to ensure everyone can make sense of them, no
matter their vision.
We should be careful not to make our design decisions based on assumptions that are often not true at all. We don’t need a “barebones” version for older users. We need a reliable, inclusive product that helps people of all groups feel independent and competent.
Bring older adults in your design process
to find out what their specific needs are. It’s not just better for
that specific target audience — good accessibility is better for
everyone. And huge kudos to wonderful people contributing to a topic
that is often forgotten and overlooked.
As
Artificial Intelligence evolves the computing paradigm, designers have
an opportunity to craft more intuitive user interfaces. Text-based Large
Language Models unlock most of the new capabilities, leading many to
suggest a shift from graphical interfaces to conversational ones like a
chatbot is necessary. However, plenty of evidence suggests conversation
is a poor interface for many interaction patterns. Maximillian Piras
examines how the latest AI capabilities can reshape the future of
human-computer interaction beyond conversation alone.
Few
technological innovations can completely change the way we interact
with computers. Lucky for us, it seems we’ve won front-row seats to the
unfolding of the next paradigm shift.
These shifts tend to unlock a
new abstraction layer to hide the working details of a subsystem.
Generalizing details allows our complex systems to appear simpler &
more intuitive. This streamlines coding programs for computers as well
as designing the interfaces to interact with them.
The Command Line Interface,
for instance, created an abstraction layer to enable interaction
through a stored program. This hid the subsystem details once exposed in
earlier computers that were only programmable by inputting 1s & 0s
through switches.
Graphical User Interfaces (GUI)
further abstracted this notion by allowing us to manipulate computers
through visual metaphors. These abstractions made computers accessible
to a mainstream of non-technical users.
Despite these advances, we still haven’t found a perfectly
intuitive interface — the troves of support articles across the web
make that evident. Yet recent advances in AI have convinced many
technologists that the next evolutionary cycle of computing is upon us.
Layers
of interface abstraction, bottom to top: Command Line Interfaces,
Graphical User Interfaces, & AI-powered Conversational Interfaces.
(Source: Maximillian Piras) (Large preview)
A branch of machine learning called generative AI
drives the bulk of recent innovation. It leverages pattern recognition
in datasets to establish probabilistic distributions that enable novel
constructions of text, media, & code. Bill Gates believes
it’s “the most important advance in technology since the graphical user
interface” because it can make controlling computers even easier. A
newfound ability to interpret unstructured data, such as natural
language, unlocks new inputs & outputs to enable novelformfactors.
Now
our universe of information can be instantly invoked through an
interface as intuitive as talking to another human. These are the
computers we’ve dreamed of in science fiction, akin to systems like Data
from Star Trek. Perhaps computers up to this point were only prototypes
& we’re now getting to the actual product launch. Imagine if
building the internet was laying down the tracks, AIs could be the
trains to transport all of our information at breakneck speed & we’re about to see what happens when they barrel into town.
“Soon
the pre-AI period will seem as distant as the days when using a
computer meant typing at a C:> prompt rather than tapping on a
screen.”
If everything is about to change, so must the mental models of software designers. As Luke Wroblewski
once popularized mobile-first design, the next zeitgeist is likely
AI-first. Only through understanding AI’s constraints & capabilities
can we craft delight. Its influence on the discourse of interface
evolution has already begun.
Large Language Models (LLMs), for
instance, are a type of AI utilized in many new applications & their
text-based nature leads many to believe a conversational interface,
such as a chatbot, is a fitting form for the future. The notion that AI
is something you talk to has been permeating across the industry for years. Robb Wilson, the co-owner of UX Magazine, calls conversation “the infinitely scalable interface” in his book The Age of Invisible Machines (2022). Noah Levin, Figma’s VP of Product Design, contends that “it’s a very intuitive thing to learn how to talk to something.” Even a herald of GUIs such as Bill Gates posits that “our main way of controlling a computer will no longer be pointing and clicking.”
Microsoft Copilot is a new conversational AI feature being integrated across their office suite. (Source: Microsoft) (Large preview)
The hope is that conversational computers will flatten learning curves. Jesse Lyu, the founder of Rabbit, asserts that a natural language approach will be “so intuitive that you don’t even need to learn how to use it.”
After
all, it’s not as if Data from Stark Trek came with an instruction
manual or onboarding tutorial. From this perspective, the evolutionary tale
of conversational interfaces superseding GUIs seems logical &
echoes the earlier shift away from command lines. But others have opposing opinions, some going as far as Maggie Appleton to call conversational interfaces like chatbots “the lazy solution.”
This
might seem like a schism at first, but it’s more so a symptom of a
simplistic framing of interface evolution. Command lines are far from
extinct; technical users still prefer them for their greater flexibility
& efficiency. For use cases like software development or automation
scripting, the added abstraction layer in graphical no-code tools can
act as a barrier rather than a bridge.
So, what is the right interface for artificially intelligent applications?
This article aims to inform that design decision by contrasting the
capabilities & constraints of conversation as an interface.
We’ll
begin with some historical context, as the key to knowing the future
often starts with looking at the past. Conversational interfaces feel
new, but we’ve been able to chat with computers for decades.
Joseph Weizenbaum invented the first chatbot, ELIZA,
during an MIT experiment in 1966. This laid the foundation for the
following generations of language models to come, from voice assistants
like Alexa to those annoying phone tree menus. Yet the majority of
chatbots were seldom put to use beyond basic tasks like setting timers.
It
seemed most consumers weren’t that excited to converse with computers
after all. But something changed last year. Somehow we went from CNET reporting that “72% of people found chatbots to be a waste of time” to ChatGPT gaining 100 million weekly active users.
A conversation with the first chatbot, ELIZA, invented in 1966. (Image source: Wikipedia) (Large preview)
What took chatbots from arid to astonishing? Most assign credit to OpenAI’s 2018 invention (PDF) of the Generative Pre-trained Transformer (GPT).
These are a new type of LLM with significant improvements in natural
language understanding. Yet, at the core of a GPT is the earlier innovation of the transformer architecture introduced in 2017
(PDF). This architecture enabled the parallel processing required to
capture long-term context around natural language inputs. Diving deeper,
this architecture is only possible thanks to the attention mechanism introduced in 2014 (PDF). This enabled the selective weighing of an input’s different parts.
Through
this assemblage of complementary innovations, conversational interfaces
now seem to be capable of competing with GUIs on a wider range of
tasks. It took a surprisingly similar path to unlock GUIs as a viable
alternative to command lines. Of course, it required hardware like a
mouse to capture user signals beyond keystrokes & screens of
adequate resolution. However, researchers found the missing software
ingredient years later with the invention of bitmaps.
Ivan Sutherland using Sketchpad’s Graphical User Interface in 1963. (Image source: ResearchGate) (Large preview)
Bitmaps
allowed for complex pixel patterns that earlier vector displays
struggled with. Ivan Sutherland’s Sketchpad, for instance, was the
inaugural GUI but couldn’t support concepts like overlapping windows.
IEEE Spectrum’s Of Mice and Menus
(1989) details the progress that led to the bitmap’s invention by Alan
Kay’s group at Xerox Parc. This new technology enabled the revolutionary
WIMP (windows, icons menus, and pointers) paradigm that helped onboard an entire generation to personal computers through intuitive visual metaphors.
Computing
no longer required a preconceived set of steps at the outset. It may
seem trivial in hindsight, but the presenters were already alluding to
an artificially intelligent system during Sketchpad’s MIT demo in 1963. This was an inflection point transforming an elaborate calculating machine into an exploratory tool.
Designers could now craft interfaces for experiences where a need to
discover eclipsed the need for flexibility & efficiency offered by
command lines.
Susan Kare’s early sketch for the pointer icon in Apple’s GUI. (Image source: It’s Nice That) (Large preview)
Novel
adjustments to existing technology made each new interface viable for
mainstream usage — the cherry on top of a sundae, if you will. In both
cases, the foundational systems were already available, but a different
data processing decision made the output meaningful enough to attract a
mainstream audience beyond technologists.
With bitmaps, GUIs can
organize pixels into a grid sequence to create complex skeuomorphic
structures. With GPTs, conversational interfaces can organize
unstructured datasets to create responses with human-like (or greater)
intelligence.
The prototypical interfaces of both paradigms were
invented in the 1960s, then saw a massive delta in their development
timelines — a case study unto itself. Now we find ourselves at another inflection point: in addition to calculating machines & exploratory tools, computers can act as life-like entities.
Geoff McFetridge’s early sketches for the conversational interface featured in the movie Her. (Image source: Gizmodo) (Large preview)
But
which of our needs call for conversational interfaces over graphical
ones? We see a theoretical solution to our need for companionship in the
movie Her, where the protagonist falls in love with his
digital assistant. But what is the benefit to those of us who are
content with our organic relationships? We can look forward to
validating the assumption that conversation is a more intuitive interface. It seems plausible because a few core components of the WIMP paradigm have well-documented usability issues.
Nielsen Norman Group
reports that cultural differences make universal recognition of icons
rare — menus trend towards an unusable mess with the inevitable addition
of complexity over time. Conversational interfaces appear more
usable because you can just tell the system when you’re confused! But
as we’ll see in the next sections, they have their fair share of
usability issues as well.
Why are conversational interfaces so popular in science fiction movies? In a Rhizome essay,
Martine Syms theorizes that they make “for more cinematic interaction
and a leaner production.” This same cost/benefit applies to app
development as well. Text completion delivered via written or spoken
word is the core capability of an LLM. This makes conversation the
simplest package for this capability from a design & engineering
perspective.
Linus Lee, a prominent AI Research Engineer, characterizes
it as “exposing the algorithm’s raw interface.” Since the interaction
pattern & components are already largely defined, there isn’t much
more to invent — everything can get thrown into a chat window.
“If
you’re an engineer or designer tasked with harnessing the power of
these models into a software interface, the easiest and most natural way
to “wrap” this capability into a UI would be a conversational
interface”
This is further validated by The Atlantic’s reporting on ChatGPT’s launch
as a “low-key research preview.” OpenAI’s hesitance to frame it as a
product suggests a lack of confidence in the user experience. The
internal expectation was so low that employees’ highest guess on
first-week adoption was 100,000 users (90% shy of the actual number).
Steve Jobs once said,
“People don’t know what they want until you show it to them.” Applying
this thinking to interfaces echoes a usability evaluation called discoverability. Nielsen Norman Group defines it as a user’s ability to “encounter new content or functionality that they were not aware of.”
A
well-designed interface should help users discover what features exist.
The interfaces of many popular generative AI applications today revolve
around an input field in which a user can type in anything to prompt
the system. The problem is that it’s often unclear what a user should type in to get ideal output. Ironically, a theoretical solution to writer’s block may have a blank page problem itself.
“I
think AI has a problem with these missing user interfaces, where, for
the most part, they just give you a blank box to type in, and then it’s
up to you to figure out what it might be able to do.”
Conversational
interfaces excel at mimicking human-to-human interaction but can fall
short elsewhere. A popular image generator named Midjourney, for
instance, only supported text input at first but is now moving towards a GUI for “greater ease of use.”
This
is a good reminder that as we venture into this new frontier, we cannot
forget classic human-centered principles like those in Don Norman’s
seminal book The Design of Everyday Things (1988). Graphical
components still seem better aligned with his advice of providing
explicit affordances & signifiers to increase discoverability.
There is also Jakob Nielsen’s list of 10 usability heuristics; many of today’s conversational interfaces seem to ignore every one of them. Consider the first usability heuristic
explaining how visibility of system status educates users about the
consequences of their actions. It uses a metaphorical map’s “You Are
Here” pin to explain how proper orientation informs our next steps.
Navigation is more relevant to conversational interfaces like chatbots than it might seem,
even though all interactions take place in the same chat window. The
backend of products like ChatGPT will navigate across a neural network
to craft each response by focusing attention on a different part of
their training datasets.
A visualization of how role-playing in prompt engineering loosely guides an AI model to craft different output. (Image source: Maximillian Piras) (Large preview)
Putting a pin on the proverbial map of their parametric knowledge isn’t trivial. LLMs are so opaque that even OpenAI admits
they “do not understand how they work.” Yet, it is possible to tailor
inputs in a way that loosely guides a model to craft a response from
different areas of its knowledge.
One popular technique for guiding attention is role-playing. You can ask an LLM to assume a role, such as by inputting “imagine you’re a historian,” to effectively switch its mode. The Prompt Engineering Institute explains
that when “training on a large corpus of text data from diverse
domains, the model forms a complex understanding of various roles and
the language associated with them.” Assuming a role invokes associated
aspects in an AI’s training data, such as tone, skills, &
rationality.
For instance, a historian role responds with factual
details whereas a storyteller role responds with narrative
descriptions. Roles can also improve task efficiency through tooling,
such as by assigning a data scientist role to generate responses with
Python code.
Roles also reinforce social norms, as Jason Yuan remarks
on how “your banking AI agent probably shouldn’t be able to have a deep
philosophical chat with you.” Yet conversational interfaces will bury
this type of system status in their message history, forcing us to keep
it in our working memory.
A
theoretical AI chatbot that uses a segmented controller to let users
specify a role in one click — each button automatically adjusts the
LLM’s system prompt. (Source: Maximillian Piras) (Large preview)
The
lack of persistent signifiers for context, like roleplay, can lead to
usability issues. For clarity, we must constantly ask the AI’s status,
similar to typing ls & cd commands into a
terminal. Experts can manage it, but the added cognitive load is likely
to weigh on novices. The problem goes beyond human memory, systems
suffer from a similar cognitive overload. Due to data limits in their
context windows, a user must eventually reinstate any roleplay below the
system level. If this type of information persisted in the interface,
it would be clear to users & could be automatically reiterated to
the AI in each prompt.
Character.ai
achieves this by using historical figures as familiar focal points.
Cultural cues lead us to ask different types of questions to “Al Pacino”
than we would “Socrates.” A “character” becomes a heuristic to set user
expectations & automatically adjust system settings. It’s like
posting up a restaurant menu; visitors no longer need to ask what there
is to eat & they can just order instead.
“Humans have
limited short-term memories. Interfaces that promote recognition reduce
the amount of cognitive effort required from users.”
Another forgotten usability lesson is that some tasks are easier to do than to explain, especially through the direct manipulation style of interaction popularized in GUIs.
Photoshop’s new generative AI features reinforce this notion by integrating with their graphical interface. While Generative Fill
includes an input field, it also relies on skeuomorphic controls like
their classic lasso tool. Describing which part of an image to
manipulate is much more cumbersome than clicking it.
Interactions should remain outside of an input field when words are less efficient.
Sliders seem like a better fit for sizing, as saying “make it bigger”
leaves too much room for subjectivity. Settings like colors & aspect
ratios are easier to select than describe. Standardized controls can
also let systems better organize prompts behind the scenes. If a model
accepts specific values for a parameter, for instance, the interface can
provide a natural mapping for how it should be input.
A
diagram of Visual Electric’s input field showcasing how graphical
controls can help a system organize a prompt behind the scenes. (Image
source: Maximilian Piras) (Large preview)
Most of these usability principles are over three decades old now, which may lead some to wonder if they’re still relevant. Jakob Nielsen recently remarked on the longevity of their relevance,
suggesting that “when something has remained true for 26 years, it will
likely apply to future generations of user interfaces as well.”
However, honoring these usability principles doesn’t require adhering to
classic components. Apps like Krea are already exploring new GUI to manipulate generative AI.
The
biggest usability problem with today’s conversational interfaces is
that they offload technical work to non-technical users. In addition to
low discoverability, another similarity they share with command lines is
that ideal output is only attainable through learned commands.
We refer to the practice of tailoring inputs to best communicate with
generative AI systems as “prompt engineering”. The name itself suggests
it’s an expert activity, along with the fact that becoming proficient in
it can lead to a $200k salary.
Programming
with natural language is a fascinating advancement but seems misplaced
as a requirement in consumer applications. Just because anyone can now
speak the same language as a computer doesn’t mean they know what to say
or the best way to say it — we need to guide them. While all new
technologies have learning curves, this one feels steep enough to hinder
further adoption & long-term retention.
Prompt engineering as a prerequisite for high-quality
output seems to have taken on the mystique of a dark art. Many marketing
materials for AI features reinforce this through terms like “magic.” If
we assume there is a positive feedback loop at play, this opaqueness
must be an inspiring consumer intrigue.
But positioning products
in the realm of spellbooks & shamans also suggests an indecipherable
experience — is this a good long-term strategy? If we assume Steve
Krug’s influential lessons from Don’t Make Me Think (2000) still apply, then most people won’t bother to study proper prompting & instead will muddle through.
But
the problem with trial & error in generative AI is that there
aren’t any error states; you’ll always get a response. For instance, if
you ask an LLM to do the math, it will provide you with confident
answers that may be completely wrong. So it becomes harder to learn from errors when we are unaware if a response is a hallucination. As OpenAI’s Andrej Karpathy suggests, hallucinations are not necessarily a bug because LLMs are “dream machines,” so it all depends on how interfaces set user expectations.
“But
as with people, finding the most meaningful answer from AI involves
asking the right questions. AI is neither psychic nor telepathic.”
Using magical language risks leading novices to the magical thinking that AI is omniscient. It may not be obvious that its knowledge is limited to the training data.
Will users know to explore different prompting techniques, such as Few-Shot or Chain of Thought, to adjust an AI’s reasoning?
Once the magic dust fades away, software designers will realize that these decisions are the user experience!
Crafting
delight comes from selecting the right prompting techniques, knowledge
sourcing, & model selection for the job to be done. We should be
exploring how to offload this work from our users.
Empty states could explain the limits of an AI’s knowledge & allow users to fill gaps as needed.
Onboarding flows could learn user goals to recommend relevant models tuned with the right reasoning.
An equivalent to fuzzy search could markup user inputs to educate them on useful adjustments.
We’ve begun to see a hint of this with OpenAI’s image generator rewriting a user’s input behind the scenes to optimize for better image output.
An
example of how combining Graphical User Interfaces with freeform inputs
can automate prompt engineering with techniques like Retrieval
Augmented Generation. (Image source: Maximillian Piras) (Large preview)
Aside from the cognitive cost of usability issues, there is a monetary cost
to consider as well. Every interaction with a conversational interface
invokes an AI to reason through a response. This requires a lot more
computing power than clicking a button within a GUI. At the current cost
of computing, this expense can be prohibitive. There are some tasks
where the value from added intelligence may not be worth the price.
For example, the Wall Street Journal
suggests using an LLM for tasks like email summarization is “like
getting a Lamborghini to deliver a pizza.” Higher costs are, in part,
due to the inability of AI systems to leverage economies of scale in the
way standard software does. Each interaction requires intense
calculation, so costs scale linearly with usage. Without a zero-marginal
cost of reproduction, the common software subscription model becomes
less tenable.
Will consumers pay higher prices for conversational
interfaces or prefer AI capabilities wrapped in cost-effective GUI?
Ironically, this predicament is reminiscent of the early struggles GUIs
faced. The processor logic & memory speed needed to power the
underlying bitmaps only became tenable when the price of RAM chips
dropped years later. Let’s hope history repeats itself.
Early
sketches for the Xerox Alto’s raster display, which had an untenable
cost until the price of RAM chips dropped. (Image source: Brett Victor) (Large preview)
Another cost to consider is the security risk:
what if your Lamborghini gets stolen during the pizza delivery? If you
let people ask AI anything, some of those questions will be
manipulative. Prompt injections
are attempts to infiltrate systems through natural language. The right
sequence of words can turn an input field into an attack vector,
allowing malicious actors to access private information & integrations.
So be cautious when positioning AI as a member of the team
since employees are already regarded as the weakest link in cyber
security defense. The wrong business logic could accidentally optimize
the number of phishing emails your organization falls victim to.
Good
design can mitigate these costs by identifying where AI is most
meaningful to users. Emphasize human-like conversational interactions at
these moments but use more cost-effective elements elsewhere. Protect
against prompt injections by partitioning sensitive data so it’s only
accessible by secure systems. We know LLMs aren’t great at math anyway,
so free them up for creative collaboration instead of managing boring
billing details.
In my previous Smashing article,
I explained the concept of algorithm-friendly interfaces. They view
every interaction as an opportunity to improve understanding through
bidirectional feedback. They provide system feedback to users while
reporting performance feedback to the system. Their success is a
function of maximizing data collection touchpoints to optimize
predictions. Accuracy gains in predictive output tend to result in
better user retention. So good data compounds in value by reinforcing
itself through network effects.
While my previous focus was on
content recommendation algorithms, could we apply this to generative AI?
While the output is very different, they’re both predictive models. We
can customize these predictions with specific data like the
characteristics, preferences, & behavior of an individual user.
So,
just as Spotify learns your musical taste to recommend new songs, we
could theoretically personalize generative AI. Midjourney could
recommend image generation parameters based on past usage or
preferences. ChatGPT could invoke the right roles at the right time
(hopefully with system status visibility).
This
territory is still somewhat uncharted, so it’s unclear how
algorithm-friendly conversational interfaces are. The same
discoverability issues affecting their usability may also affect their
ability to analyze engagement signals. An inability to separate signal
from noise will weaken personalization efforts. Consider a simple
interaction like tapping a “like” button; it sends a very clean signal
to the backend.
What is the conversational equivalent of this?
Inputting the word “like” doesn’t seem like as reliable a signal because
it may be mentioned in a simile or mindless affectation. Based on the
insights from my previous article, the value of successful
personalization suggests that any regression will be acutely felt in
your company’s pocketbook.
Perhaps a solution is using another LLM
as a reasoning engine to format unstructured inputs automatically into
clear engagement signals. But until their data collection efficiency is
clear, designers should ask if the benefits of a conversational interface outweigh the risk of worse personalization.
As
this new paradigm shift in computing evolves, I hope this is a helpful
primer for thinking about the next interface abstractions.
Conversational interfaces will surely be a mainstay in the next era of
AI-first design. Adding voice capabilities will allow computers to
augment our abilities without arching our spines through unhealthy
amounts of screen time. Yet conversation alone won’t suffice, as we also
must design for needs that words cannot describe.
So, if no
interface is a panacea, let’s avoid simplistic evolutionary tales &
instead aspire towards the principles of great experiences. We want an
interface that is integrated, contextual, & multimodal.
It knows sometimes we can only describe our intent with gestures or
diagrams. It respects when we’re too busy for a conversation but need to
ask a quick question. When we do want to chat, it can see what we see, so we aren’t burdened with writing lengthy descriptions. When words fail us, it still gets the gist.
This
moment reminds me of a cautionary tale from the days of mobile-first
design. A couple of years after the iPhone’s debut, touchscreens became a
popular motif in collective visions of the future. But Bret Victor, the
revered Human-Interface Inventor (his title at Apple), saw touchscreens more as a tunnel vision of the future.
In his brief rant
on peripheral possibilities, he remarks how they ironically ignore
touch altogether. Most of the interactions mainly engage our sense of
sight instead of the rich capabilities our hands have for haptic
feedback. How can we ensure that AI-first design amplifies all our
capabilities?
“A tool addresses human needs by amplifying human capabilities.”
I
wish I could leave you with a clever-sounding formula for when to use
conversational interfaces. Perhaps some observable law stating that the
mathematical relationship expressed by D∝1/G elucidates that ‘D’,
representing describability, exhibits an inverse correlation with ‘G’,
denoting graphical utility — therefore, as the complexity it takes to
describe something increases, a conversational interface’s usability
diminishes. While this observation may be true, it’s not very useful.
Honestly,
my uncertainty at this moment humbles me too much to prognosticate on
new design principles. What I can do instead is take a lesson from the
recently departed Charlie Munger & invert the problem.
We
often design forwards by seeking brilliance, but sometimes we need to
design backwards by inverting the problem to avoid stupidity. (Image
source: Maximillian Piras) (Large preview)
If
we try to design the next abstraction layer looking forward, we seem to
end up with something like a chatbot. We now know why this is an
incomplete solution on its own. What if we look at the problem backward to identify the undesirable outcomes that we want to avoid? Avoiding stupidity is easier than seeking brilliance, after all.
An
obvious mistake to steer clear of is forcing users to engage in
conversations without considering time constraints. When the time is
right to chat, it should be in a manner that doesn’t replace existing
usability problems with equally frustrating new ones. For basic tasks of
equivalent importance to delivering pizza, we should find practical
solutions not of equivalent extravagance to driving a Lamborghini.
Furthermore, we ought not to impose prompt engineering expertise as a
requirement for non-expert users. Lastly, as systems become more
human-like, they should not inherit our gullibility, lest our efforts
inadvertently optimize for exponentially easier access to our private
data.
A more intelligent interface won’t make those stupid mistakes.
Most
product teams commonly adopt a feature-centric mindset, finding them
convenient for brainstorming, drafting requirement documents, and
integrating into backlogs and ticketing systems. In this article, Andy
Budd shows how fixation with features might be holding you back and how
making a few small tweaks to your process could make an entire world of
difference.
Most product teams think in terms of
features. Features are easy to brainstorm and write requirement docs
for, and they fit nicely into our backlogs and ticketing systems. In
short, thinking in terms of features makes it easy to manage the complex
task of product delivery.
However, we know that the best products are more
than the sum of their parts, and sometimes, the space between the
features is as important as the features themselves. So, what can we do
to improve the process?
The vast majority of product teams are
organized around delivering features — new pieces of functionality that
extend the capabilities of the product. These features will often arise
from conversations the company is having with prospective buyers:
“What features are important to you?”
“What features are missing from your current solution?”
“What features would we need to add in order to make you consider switching from your existing provider to us?” and so on.
The company will then compile a list of the most popular feature requests and will ask the product team to deliver them.
For most companies, this is what customer centricity
looks like; asking customers to tell them what they want — and then
building those features into the product in the hope they’ll buy —
becomes of key importance. This is based on the fundamental belief that
people buy products primarily for the features so we assemble our roadmaps accordingly.
We
see this sort of thinking with physical products all the time. For
instance, take a look at the following Amazon listing for one of the
top-rated TV sets from last year. It’s like they hurled up the entire
product roadmap directly onto the listing!
An Amazon listing for one of the top-rated TV from last year. It isn’t very engaging, is it? (Large preview)
Now,
of course, if you’re a hardcore gamer with very specific requirements,
you might absolutely be looking for a TV with “VRR, ALLM, and eARC as
specified in HDMI2.1, plus G-Sync, FreeSync, Game Optimizer, and HGiG.”
But for me? I don’t have a clue what any of those things mean, and I
don’t really care. Instead, I’ll go to a review site where they explain
what the product actually feels like to use in everyday life.
The reviewers will explain how good the unboxing experience is. How
sturdy the build is. How easy it is to set up. They’ll explain that the
OS is really well put together and easy to navigate, the picture quality
is probably the best on the market, and the sound, while benefiting
from the addition of a quality sound bar, is very clear and
understandable. In short, they’ll be describing the user experience.
The
ironic thing is that when I talk to most founders, product managers,
and engineers about how they choose a TV, they’ll say exactly the same
thing. And yet, for some reason, we struggle to take that personal
experience and apply it to our own users!
Tip: As a fun little trick, next time you find yourself arguing about features over experience,
ask people to get out their phones. I bet that the vast majority of
folks in the room will have an iPhone, despite Samsung and Google phones
generally having better cameras, more storage, better screens, and so
on. The reason why iPhones have risen in dominance (if we ignore the
obvious platform lock-in) is because, despite perhaps not having the
best feature set on the market, they feel so nice to use.
A conference room full of people. How many people here have an iPhone vs another brand? (Image credit: Alexandre Pellaes) (Large preview)
While
feature-centric thinking is completely understandable, it misses a
whole class of problems. The features in and of themselves might look
good on paper and work great in practice, but do they mesh together to
form a convincing whole? Or is the full experience a bit of a mess?
If users are already struggling to extract value from existing features, how do you expect them to extract any additional value you might be adding to the product?
“As
a product manager, it’s natural to want to offer as many features as
possible to your customers. After all, you want to provide value, right?
But what happens when you offer too many features? Your product becomes
bloated, convoluted, and difficult to use.” — “Are Too Many Features Hurting Your Product?”
These barriers and inconsistencies are usually the result of people not thinking through the user experience. And I don’t mean user experience
in some abstract way. I mean literally walking through the product
step-by-step as though you’d never seen it before — sometimes described
as having a “beginner’s mind” — and considering the following questions:
Is it clear what value this product delivers and how I can get that value?
If I were a new user, would the way the product is named and structured make sense to me?
Can I easily build up a mental model of where everything is and how the product works?
Do I know what to do next?
How is this going to fit into my existing workflow?
What’s getting in my way and slowing me down?
While
approaching things with a beginner’s mind sounds easy, it’s actually a
surprisingly hard mindset for people to adopt — letting go of everything
they know (or think they know) about their product, market, and users.
Instead, their position as a superuser tends to cloud their judgment:
believing that because something is obvious to them (something that they
have created and have been working on for the past two years), it will
be obvious to a new user who has spent less than five minutes with the
product. This is where usability testing
(a UX research method that evaluates whether users are able to use a
digital product efficiently and effectively) should normally “enter the
stage.”
The issue with trying to approach things with a beginner’s mind is also often exacerbated by “motivated reasoning,” the idea that we view things through the lens of what we want to be true, rather than what is
true. To this end, you’re much more likely to discount feedback from
other people if that feedback is going to result in some negative
outcome, like having to spend extra time and money redesigning a user
flow when you’d rather be shipping that cool new feature you came up
with last week.
I see this play out in usability testing sessions
all the time. The first subject comes in and struggles to grasp a core
concept, and the team rolls their eyes at the incompetence of the user.
The next person comes in and has the same experience, causing the team
to ask where you found all these stupid users. However, as the third,
fourth, and fifth person comes through and experiences the same
challenge, “lightbulbs” slowly start forming over the team members’
heads:
“Maybe this isn’t the users’ fault after all?
Maybe we’ve assumed a level of knowledge or motivation that isn’t there;
maybe it’s the language we’ve used to describe the feature, or maybe
there’s something in the way the interface has been designed that is
causing this confusion?”
These kinds of insights can
cause teams to fundamentally pivot their thinking. But this can also
create a huge amount of discomfort and cognitive dissonance — realizing
that your view of the world might not be entirely accurate. As such,
there’s a strong motivation for people to avoid these sorts of
realizations, which is why we often put so little effort (unfortunately)
into understanding how our users perceive and use the things we create.
Developing
a beginner’s mind takes time and practice. It’s something that most
people can cultivate, and it’s actually something I find designers are
especially good at — stepping into other people’s shoes, unclouded by
their own beliefs and biases. This is what designers mean when they talk
about using empathy.
We
obviously still need to have “feature teams.” Folks who can understand
and deliver the new capabilities our users request (and our business
partners demand). While I’d like to see more thought and validation when
it comes to feature selection and creation, it’s often quicker to add new features to see if they get used than to try and use research to give a definitive answer.
As
an example, I’m working with one founder at the moment who has been
going around houses with their product team for months about whether a
feature would work. He eventually convinced them to give it a try — it
took four days to push out the change, and they got the feedback they
needed almost instantly.
However, as well as having teams focused on delivering new user value, we also need teams who are focused on helping unlock and maximize existing user value. These teams need to concentrate on outcomes over outputs; so, less deliver X capability in Y sprints than deliver X improvement by Y date.
To do this, these teams need to have a high level of agency. This means
taking them out of the typical feature factory mindset.
The
teams focusing on helping unlock and maximize existing user value need
to be a little more cross-disciplinary than your traditional feature
team. They’re essentially developing interventions rather than new
capabilities — coming up with a hypothesis and running experiments
rather than adding bells and whistles. “How can we improve the onboarding experience to increase activation and reduce churn?” Or, “How
can we improve messaging throughout the product so people have a better
understanding of how it works and increase our North Star metric as a
result?”
There’s nothing radical about focusing on outcomes over outputs. In fact, this way of thinking is at the heart of both the Lean Startup movement and the Product Led Growth.
The problem is that while this is seen as received wisdom, very few
companies actually put it into practice (although if you ask them, most
founders believe that this is exactly what they do).
So
this two-tier system is really a hack, allowing you to keep sales,
marketing, and your CEO (and your CEO’s partner) happy by delivering a
constant stream of new features while spinning up a separate team who
can remove themselves from the drum-beat of feature delivery and focus
on the outcomes instead.
“Why Too Many Features Can Ruin a Digital Product Before It Begins” (Komodo Digital) Digital
products are living, ever-evolving things. So, why do so many companies
force feature after feature into projects without any real
justification? Let’s talk about feature addiction and how to avoid it.
“Are Too Many Features Hurting Your Product?” (FAQPrime) As
a product manager, it’s natural to want to offer as many features as
possible to your customers. After all, you want to provide value, right?
But what happens when you offer too many features? Your product becomes
bloated, convoluted, and difficult to use. Let’s take a closer look at
what feature bloat is, why it’s a problem, and how you can avoid it.
“What Is The Agile Methodology?,” (Atlassian) The
Agile methodology is a project management approach that involves
breaking the project into phases and emphasizes continuous collaboration
and improvement. Teams follow a cycle of planning, executing, and
evaluating.
“Problem Statement vs Hypothesis — Which Is More Important?,” Sadie Neve When
it comes to experimentation and conversion rate optimization (CRO), we
often see people relying too much on their instincts. But in reality,
nothing in experimentation is certain until tested. This means
experimentation should be approached like a scientific experiment that
follows three core steps: identify a problem, form a hypothesis, and
test that hypothesis.
“The Build Trap,” Melissa Perri (Produx Labs) The “move fast and break things”
mantra seems to have taken the startup world by storm since Facebook
made it their motto a few years ago. But there is a serious flaw with
this phrase, and it’s that most companies see this as an excuse to stop
analyzing what they intend to build and why they should build it — those
companies get stuck in what I call “The Build Trap.”
“What Is Product-led Growth?” (PLG Collective) We
are in the middle of a massive shift in the way people use and buy
software. It’s been well over a decade since Salesforce brought software
to the cloud. Apple put digital experiences in people’s pockets back in
2009 with the first iPhone. And in the years since the market has been
flooded with consumer and B2B products that promise to meet just about
every need under the sun.
The Lean Startup The
Lean Startup isn’t just about how to create a more successful
entrepreneurial business. It’s about what we can learn from those
businesses to improve virtually everything we do.
“Usability Testing — The Complete Guide,” Daria Krasovskaya and Marek Strba Usability
testing is the ultimate method of uncovering any type of issue related
to a system’s ease of use, and it truly is a must for any modern website
or app owner.
“The Value of Great UX,” Jared Spool How
can we show that a great user experience produces immense value for the
organization? We can think of experience as a spectrum, from extreme
frustration to delight. In his article, Jared will walk you through how
our work as designers is able to transform our users’ experiences from
being frustrated to being delighted.
“Improving The Double Diamond Design Process,” Andy Budd (Smashing Magazine) The
so-called “Double Diamond” is a great way of visualizing an ideal
design process, but it’s just not the way most companies deliver new
projects or services. The article proposes a new “Double Diamond” idea
that better aligns with the way work actually gets done and highlights
the place where design has the most leverage.
“Are We Moving Towards a Post-Agile Age?,” Andy Budd Agile
has been the dominant development methodology in our industry for a
while now. While some teams are just getting to grips with Agile, others
have extended it to the point that it’s no longer recognizable as
Agile; in fact, many of the most progressive design and development
teams are Agile only in name. What they are actually practicing is
something new, different, and innately more interesting — something I’ve
been calling Post-Agile thinking.
Language
models have shown impressive capabilities. But that doesn’t mean
they’re without faults, as anyone who has witnessed a ChatGPT
“hallucination” can attest. Retrieval Augmented Generation (RAG) is a
framework designed to make language models more reliable by pulling in
relevant, up-to-date data directly related to a user’s query. In this
article, Joas Pambou diagnoses the symptoms that cause hallucinations
and explains not only what RAG is but also different approaches for
using it to solve language model limitations.
Suppose
you ask some AI-based chat app a reasonably simple, straightforward
question. Let’s say that app is ChatGPT, and the question you ask is
right in its wheelhouse, like, “What is Langchain?” That’s
really a softball question, isn’t it? ChatGPT is powered by the same
sort of underlying technology, so it ought to ace this answer.
So,
you type and eagerly watch the app spit out conversational strings of
characters in real-time. But the answer is less than satisfying.
In
fact, ask ChatGPT — or any other app powered by language models — any
question about anything recent, and you’re bound to get some sort of
response along the lines of, “As of my last knowledge update…” It’s like ChatGPT fell asleep Rumplestiltskin-style back in January 2022 and still hasn’t woken up. You know how people say, “You’d have to be living under a rock not to know that”? Well, ChatGPT took up residence beneath a giant chunk of granite two years ago.
While many language models are trained on massive datasets, data is still data, and data becomes stale. You might think of it like Googling “CSS animation,” and the top result is a Smashing Magazine article from 2011.
It might still be relevant, but it also might not. The only difference
is that we can skim right past those instances in search results while
ChatGPT gives us some meandering, unconfident answers we’re stuck with.
There’s also the fact that language models are only as “smart” as the data used to train them.
There are many techniques to improve language model’s performance, but
what if language models could access real-world facts and data outside
their training sets without extensive retraining? In other words, what
if we could supplement the model’s existing training with accurate,
timely data?
This is exactly what Retrieval Augmented Generation (RAG)
does, and the concept is straightforward: let language models fetch
relevant knowledge. This could include recent news, research, new
statistics, or any new data, really. With RAG, a large language model
(LLM) is able to retrieve “fresh” information for more high-quality
responses and fewer hallucinations.
But what exactly does RAG make
available, and where does it fit in a language chain? We’re going to
learn about that and more in this article.
Unlike keyword search, which relies on exact word-for-word matching, semantic search
interprets a query’s “true meaning” and intent — it goes beyond merely
matching keywords to produce more results that bear a relationship to
the original query.
For example, a semantic search querying “best
budget laptops” would understand that the user is looking for
“affordable” laptops without querying for that exact term. The search recognizes the contextual relationships between words.
This works because of text embeddings
or mathematical representations of meaning that capture nuances. It’s
an interesting process of feeding a query through an embedded model
that, in turn, converts the query into a set of numeric vectors that can
be used for matching and making associations.
Text embedding is a technique for representing text data in a numerical format. (Large preview)
The
vectors represent meanings, and there are benefits that come with it,
allowing semantic search to perform a number of useful functions, like scrubbing irrelevant words from a query, indexing information for efficiency, and ranking results based on a variety of factors such as relevance.
Special
databases optimized for speed and scale are a strict necessity when
working with language models because you could be searching through
billions of documents. With a semantic search implementation that
includes test embedding, storing and querying high-dimensional embedding
data is much more efficient, producing quick and efficient evaluations
on queries against document vectors across large datasets.
That’s the context we need to start discussing and digging into RAG.
Retrieval Augmented Generation (RAG) is based on research produced by the Meta team
to advance the natural language processing capabilities of large
language models. Meta’s research proposed combining retriever and
generator components to make language models more intelligent and
accurate for generating text in a human voice and tone, which is also
commonly referred to as natural language processing (NLP).
At
its core, RAG seamlessly integrates retrieval-based models that fetch
external information and generative model skills in producing natural
language. RAG models
outperform standard language models on knowledge-intensive tasks like
answering questions by augmenting them with retrieved information; this
also enables more well-informed responses.
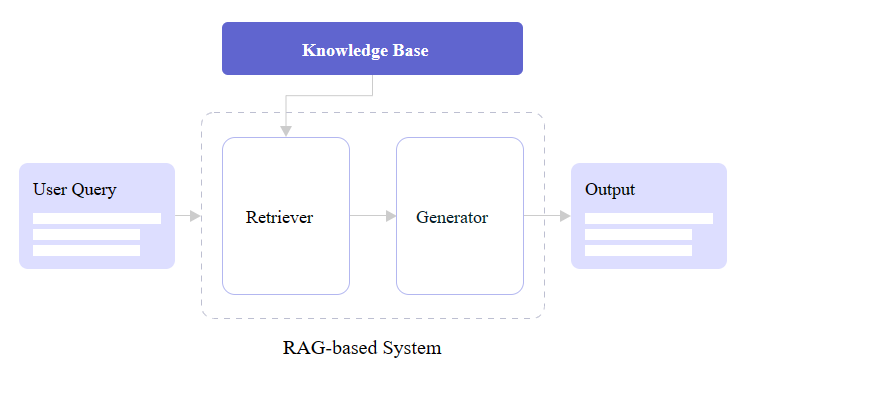
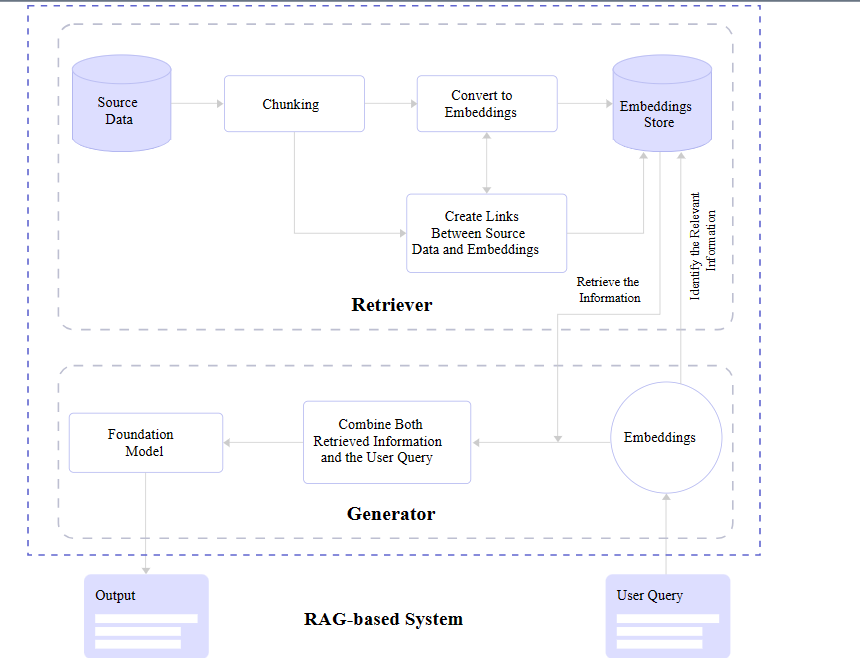
Diagramming the integration of retriever and generator components. (Large preview)
You may notice in the figure above that there are two core RAG components: a retriever and a generator. Let’s zoom in and look at how each one contributes to a RAG architecture.
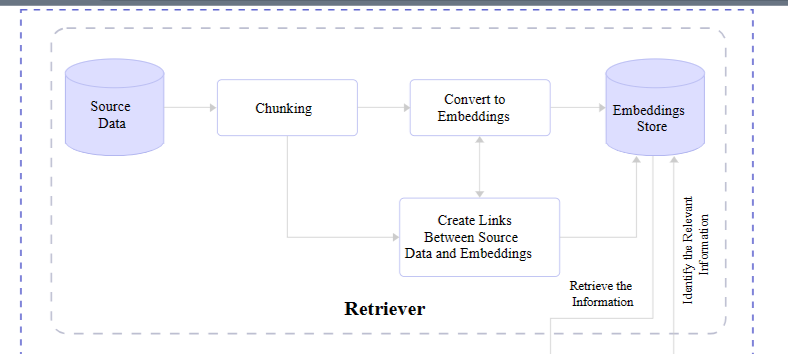
We already covered it briefly, but a retriever module
is responsible for finding the most relevant information from a dataset
in response to queries and makes that possible with the vectors
produced by text embedding. In short, it receives the query and retrieves what it evaluates to be the most accurate information based on a store of semantic search vectors.
Diagramming the flow of a retreiver module. (Large preview)
Retrievers
are models in and of themselves. But unlike language models, retrievers
are not in the business of “training” or machine learning. They are
more of an enhancement or an add-on that provides additional context for
understanding and features for fetching that information efficiently.
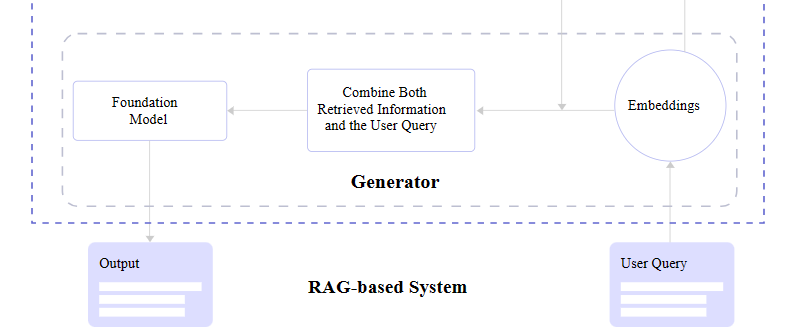
After
the retriever finds relevant information, it needs to be passed back to
the application and displayed to the user. Or what’s needed is a generator capable of converting the retrieved data into human-readable content.
Diagramming a generator flow in a RAG-based system. (Large preview)
What’s
happening behind the scenes is the generator accepts the embeddings it
receives from the retriever, mashes them together with the original
query, and passes through the trained language model for an NLP pass on
the way to becoming generated text.
The entire tail end of that
process involving the language model and NLP is a process in its own
right and is something I have explained in greater detail in another Smashing Magazine article if you are curious about what happens between the generator and final text output.
We opened this article up by describing “hallucinations” in LLMs’ incorrect responses or something along the lines of “I don’t know, but here’s what I do know.” The LLM will “make stuff up” because it simply doesn’t have updated information to respond with.
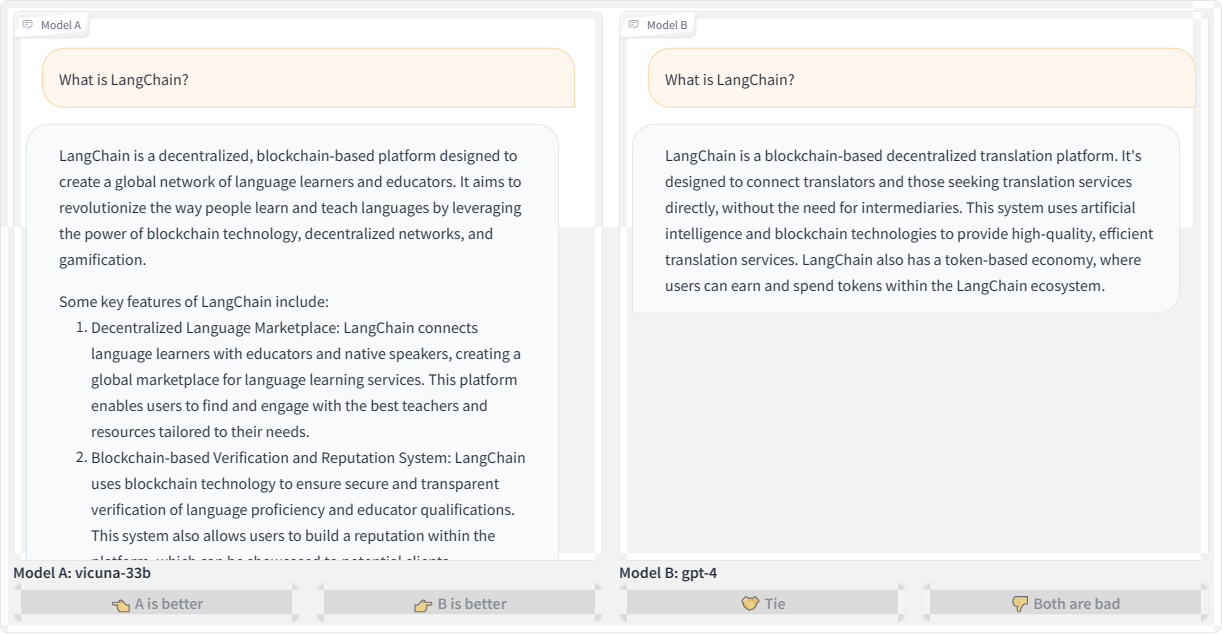
Let’s revisit the first query we used to kick off this article — “What is LangChain?” — and compare responses from the Vicuna and GPT-4 language models:
Chat responses showing hallucinations in Vicuna and GPT-4. (Large preview)
Here’s the transcription for the second query using OpenAI’s GPT-4 for posterity:
“LangChain
is a blockchain-based decentralized translation platform. It’s designed
to connect translators and those seeking translation services directly
without the need for intermediaries. This system uses artificial
intelligence and blockchain technologies to provide high-quality,
efficient translation services. LangChain also has a token-based
economy, where users can earn and spend tokens within the LangChain
ecosystem.”
Both Vicuna and GPT-4 refer to LangChain as a
blockchain platform. Blockchain is a technology that stores data in a
decentralized manner using chained blocks, so the models’ responses
sound plausible given the “chain” in the name. However, LangChain is not
actually a blockchain-based technology.
This is a prime example
demonstrating how LLMs will fabricate responses that may seem believable
at first glance but are incorrect. LLMs are designed to predict the
next “plausible” tokens in a sequence, whether those are words,
subwords, or characters. They don’t inherently understand the full
meaning of the text. Even the most advanced models struggle to avoid
made-up responses, especially for niche topics they lack knowledge
about.
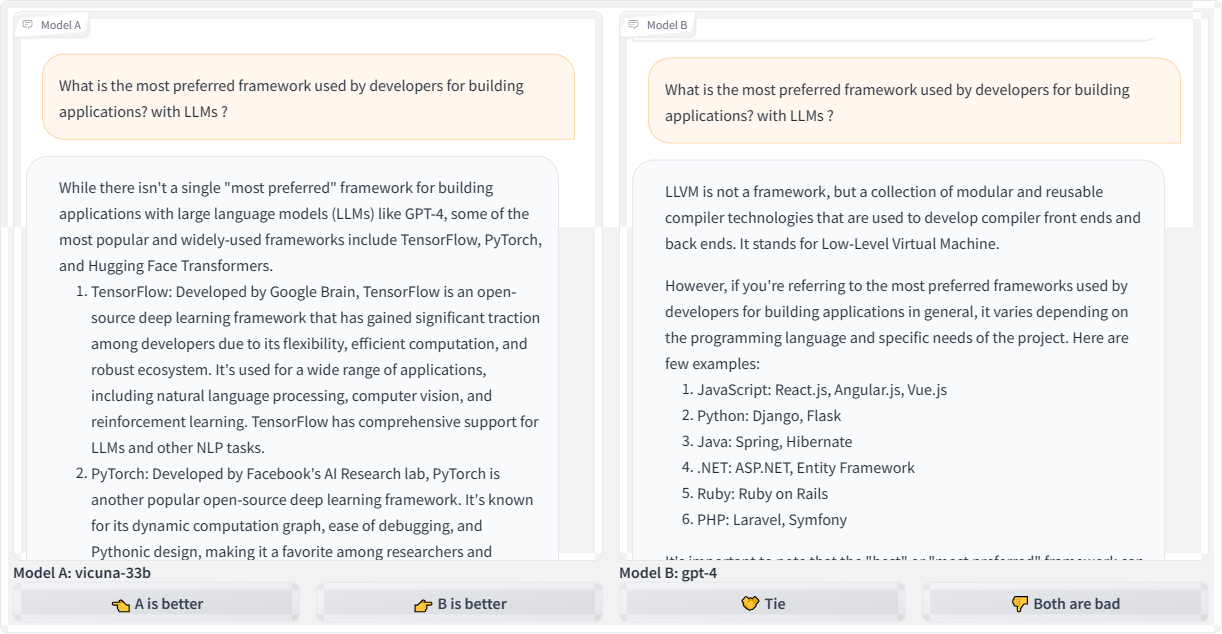
Let’s look at another example by querying: “What is the most preferred framework used by developers for building applications leveraging large language models?”
Two responses generated by Vicuna & GPT-4 language models. (Large preview)
While
Vicuna offers a couple of reasonable starting points for answering the
question, the frameworks it refers to have limitations for efficiency
and scalability in production-level applications that use LLMs. That
could quite possibly send a developer down a bad path. And as bad as
that is, look at the GPT-4 response that changes topics completely by
focusing on LLVM, which has nothing to do with LLMs.
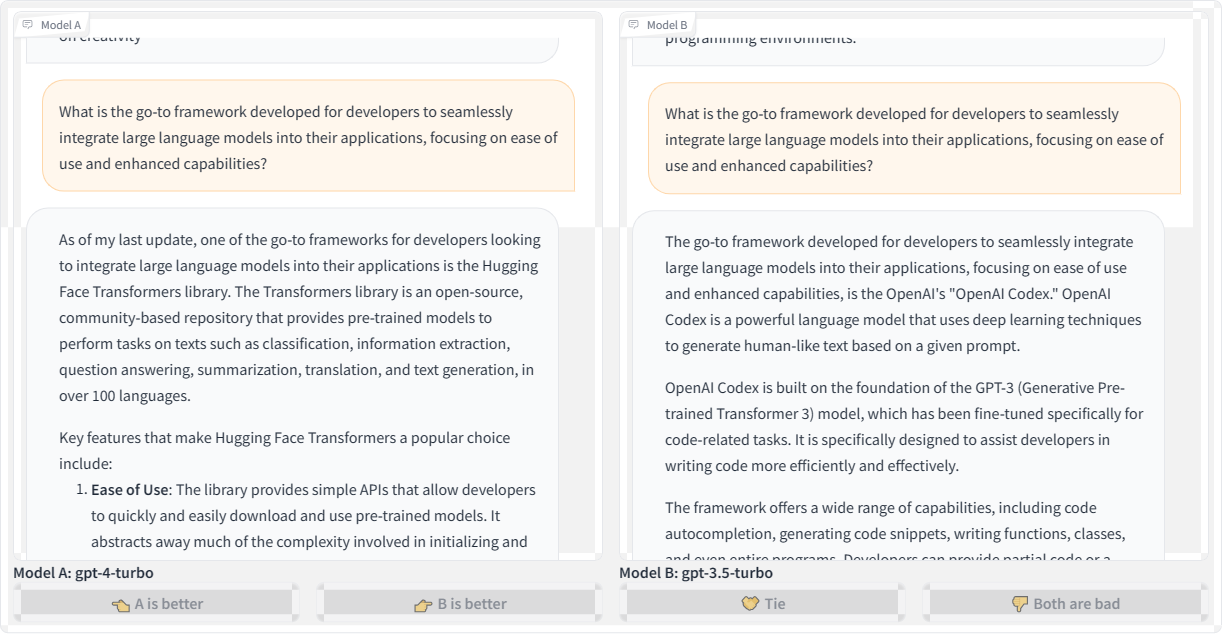
What if we
refine the question, but this time querying different language models?
This time, we’re asking: “What is the go-to framework developed for
developers to seamlessly integrate large language models into their
applications, focusing on ease of use and enhanced capabilities?”
Example of hallucinated chats of GPT-3.5 & GPT-4. (Large preview)
Honestly,
I was expecting the responses to refer to some current framework, like
LangChain. However, the GPT-4 Turbo model suggests the “Hugging Face”
transformer library, which I believe is a great place to experiment with
AI development but is not a framework. If anything, it’s a place where
you could conceivably find tiny frameworks to play with.
Meanwhile, the GPT-3.5 Turbo model produces a much more confusing response, talking about OpenAICodex as a framework, then as a language model. Which one is it?
We
could continue producing examples of LLM hallucinations and inaccurate
responses and have fun with the results all day. We could also spend a
lot of time identifying and diagnosing what causes hallucinations. But
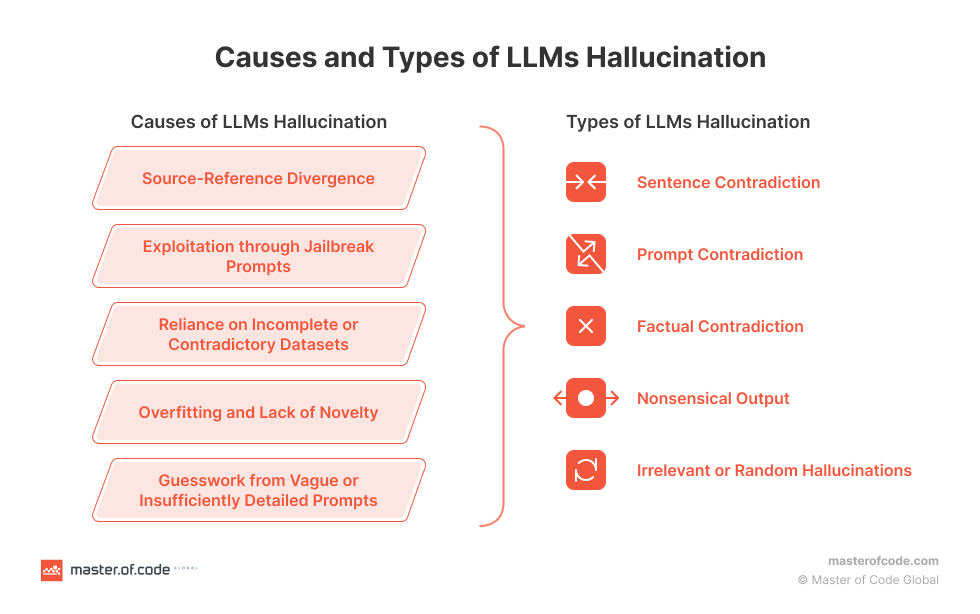
we’re here to talk about RAG and how to use it to prevent hallucinations from happening in the first place. The Master of Code Global blog has an excellent primer on the causes and types of LLM hallucinations with lots of useful context if you are interested in diving deeper into the diagnoses.
OK,
so we know that LLMs sometimes “hallucinate” answers. We know that
hallucinations are often the result of outdated information. We also
know that there is this thing called Retrieval Augmented Generation that
supplements LLMs with updated information.
Now that you have a good understanding of RAG and
its benefits, we can dive into how to implement it yourself. This
section will provide hands-on examples to show you how to code RAG
systems and feed new data into your LLM.
But before jumping right into the code, you’ll need to get a few key things set up:
Hugging Face We’ll
use this library in two ways. First, to choose an embedding model from
the model hub that we can use to encode our texts, and second, to get an
access token so we can download the Llama-2 model. Sign up for a free
Hugging Face in preparation for the work we’ll cover in this article.
Next, we need to import specific modules from those libraries. There are quite a few that we want, like ChromaVectorStore and HuggingFaceEmbedding for vector indexing and embeddings capabilities, storageContext and chromadb
to provide database and storage functionalities, and even more for
computations, displaying outputs, loading language models, and so on.
This can go in a file named app.py at the root level of your project.
## app.py## Import necessary librariesfrom llama_index import VectorStoreIndex, download_loader, ServiceContext
from llama_index.vector_stores import ChromaVectorStore
from llama_index.storage.storage_context import StorageContext
from llama_index.embeddings import HuggingFaceEmbedding
from llama_index.response.notebook_utils import display_response
import torch
from transformers import BitsAndBytesConfig
from llama_index.prompts import PromptTemplate
from llama_index.llms import HuggingFaceLLM
from IPython.display import Markdown, display
import chromadb
from pathlib import Path
import logging
import sys
The data we will leverage for our language model is a research paper titled “Enhancing LLM Intelligence with ARM-RAG: Auxiliary Rationale Memory for Retrieval Augmented Generation” (PDF) that covers an advanced retrieval augmentation generation approach to improve problem-solving performance.
We will use the download_loader() module we imported earlier from llama_index to download the PDF file:
Even
though this demonstration uses a PDF file as a data source for the
model, that is just one way to supply the model with data. For example,
there is Arxiv Papers Loader as well as other loaders available in the LlamaIndex Hub.
But for this tutorial, we’ll stick with loading from a PDF. That said, I
encourage you to try other ingestion methods for practice!
Now, we need to download Llama-2, our open-source text generation model from Meta. If you haven’t already, please set up an account with Meta and have your access token available with read permissions, as this will allow us to download Llama-2 from Hugging Face.
# huggingface api token for downloading llama2
hf_token ="YOUR Access Token"
To fit Llama-2 into constrained memory, like in Google Colab, we’ll configure 4-bit quantization to load the model at a lower precision.
Google Colab is where I typically do most of my
language model experiments. We’re shrinking the language model down with
that last snippet so it’s not too large for Colab to support.
Next, we need to initialize HuggingFaceLLM to set up our model for generating text on the fly:
Note
that what’s happening here is that we’ve defined our model (Llama-2),
but a specific subset of it is designed for a chat UI (Llama-2-Chat).
Even though this is what we are using for this article, you can also
pick from other text generation models in the Hugging Face hub, such as Neural-chat from Intel.
OK,
so we have the model loaded and configured. Let’s try it out by asking
it questions that it could reasonably answer using the content we
provided via the ARM-RAG PDF file to see how the model responds without
any context. The following code is for displaying the text output without the PDF providing data to the model for comparison sake:
from IPython.display import HTML, display
# Assuming resp contains the response
resp = llm.complete("What is ARM-RAG?")# Using HTML with inline CSS for styling (gray color, smaller font size)
html_text =f'<p style="color: #1f77b4; font-size: 14px;"><b>{resp}</b></p>'
Let’s see the response:
display(HTML(html_text))
ARM-RAG (ARM Register-Allocating Generator)is a register allocation algorithm used in compiler design. nobody knows who invented it, but it was first described in a 1995 paper by Mark H. T. Kim and Andrew Y. Chen. The ARM-RAG algorithm is a register-allocating generator, meaning it is a heuristic algorithm that takes a program asinputand generates a register allocation plan for it. The goal of the algorithm is to assign registers to variables in a way that minimizes the number of spills (i.e., loads or stores to/from memory)while satisfying all the memory access constraints of the program. The ARM-RAG algorithm works by first partitioning the program into a set of basic blocks,and then iteratively allocating registers to variables within each basic block. The algorithm uses a cost function to evaluate the quality of each allocation,and it selects the allocation with the lowest cost. The cost function takes into account factors such as the distance between the variable and the current register, the distance between the variable and the next allocation,and the number of spills that would be required to allocate the variable. ARM-RAG
Obviously,
without any context from the PDF file, the model generates a
hallucinated response that describes some unrelated algorithm. To fix
this, we need to provide relevant passages from the paper to ground
Llama-2’s responses. We’ll encode the document into embeddings and index
them for retrieval; then, when we query, we can feed LLama-2 relevant
retrieved passages to steer it toward accurate, on-topic responses based
on the contents of the PDF file.
First, we need to create a client to interact with our ChromaDB database and a new collection that will hold our vector index.
# create client and a new collection
chroma_client = chromadb.EphemeralClient()
chroma_collection = chroma_client.create_collection("firstcollection")
Then we need to set up the HuggingFaceEmbedding class with the specified model name for embedding the text into vectors:
# Load the embedding model
embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-base-en-v1.5")
This initializes HuggingFaceEmbedding, passing the name of the pre-trained model we want to use, BAAI/bge-base-en-v1.5. There are other options, of course.
Now, we can set up the vector store and use it to index the embedded document vectors:
# set up ChromaVectorStore and load in data
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
service_context = ServiceContext.from_defaults(llm=llm, embed_model=embed_model)
index = VectorStoreIndex.from_documents(
documents, storage_context=storage_context, service_context=service_context
)
This creates a ChromaVectorStore connected to our collection, defines the storage and service contexts, and generates a VectorStoreIndex
from the loaded documents using the embedding model. The index is what
allows us to quickly find relevant passages for a given query to augment
the quality of the model’s response.
We should also establish a way for the model to summarize the data rather than spitting everything out at once. A SummaryIndex offers efficient summarization and retrieval of information:
Earlier,
the model hallucinated when we queried it without the added context
from the PDF file. Now, let’s ask the same question, this time querying
our indexed data:
#Define your query
query="what is ARM-RAG?"from llama_index.embeddings.base import similarity
query_engine =index.as_query_engine(response_mode="compact")
response = query_engine.query(query)from IPython.display import HTML, display
# Using HTML with inline CSS for styling (blue color)
html_text =f'<p style="color: #1f77b4; font-size: 14px;"><b>{response}</b></p>'
display(HTML(html_text))
Here’s the output:
Final Response: Based on the context information provided, ARM-RAG is a system that utilizes Neural Information Retrieval to archive reasoning chains derived from solving grade-school math problems. It is an Auxiliary Rationale Memory for Retrieval Augmented Generation, which aims to enhance the problem-solving capabilities of Large Language Models (LLMs). The system surpasses the performance of a baseline system that relies solely on LLMs, demonstrating the potential of ARM-RAG to improve problem-solving capabilities.
Correct! This response is way better than the one we saw earlier — no hallucinations here.
Since
we’re using the chat subset of the Llama-2 model, we could have a
back-and-forth conversation with the model about the content of the PDF
file with follow-up questions. That’s because the indexed data supports
NLP.
chat_engine = index.as_chat_engine(chat_mode="condense_question", verbose=True)
response = chat_engine.chat("give me real world examples of apps/system i can build leveraging ARM-RAG?")print(response)
This is the resulting output:
Querying with: What are some real-world examples of apps or systems that can be built leveraging the ARM-RAG framework, which was discussed in our previous conversation?
Based on the context information provided, the ARM-RAG framework can be applied to various real-world examples, including but not limited to:1. Education: ARM-RAG can be used to develop educational apps that can help students learn and understand complex concepts by generating explanations and examples that can aid in their understanding.2. Tutoring: ARM-RAG can be applied to tutoring systems that can provide personalized explanations and examples to students, helping them grasp difficult concepts more quickly and effectively.3. Customer Service: ARM-RAG can be utilized in chatbots or virtual assistants to provide customers with detailed explanations and examples of products or services, enabling them to make informed decisions.4. Research: ARM-RAG can be used in research environments to generate explanations and examples of complex scientific concepts, enabling researchers to communicate their findings more effectively to a broader audience.5. Content Creation: ARM-RAG can be applied to content creation systems that can generate explanations and examples of complex topics, such as news articles, blog posts,or social media content, making them more engaging and easier
Try
asking more questions! Now that the model has additional context to
augment its existing dataset, we can have a more productive — and
natural — interaction.
The
whole point of this article is to explain the concept of RAG and
demonstrate how it can be used to enhance a language model with accurate
and updated data.
Chroma and LlamaIndex were the main components
of the demonstrated RAG approach, but there are other tools for
integrating RAG with language models. I’ve prepared a table that
outlines some popular options you might consider trying with your own
experiments and projects.
In
this article, we examined examples of language models producing
“hallucinated” responses to queries as well as possible causes of those
hallucinations. At the end of the day, a language model’s responses are only as good as the data it provided,
and as we’ve seen, even the most widely used models consist of outdated
information. And rather than admit defeat, the language model spits out
confident guesses that could be misconstrued as accurate information.
Retrieval Augmented Generation is one possible cure for hallucinations.
We
did this by registering a PDF file with the model that contains content
the model could use when it receives a query on a particular subject,
in this case, “Enhancing LLM Intelligence with ARM-RAG: Auxiliary
Rationale Memory for Retrieval Augmented Generation.”
This, of
course, was a rather simple and contrived example. I wanted to focus on
the concept of RAG more than its capabilities and stuck with a single
source of new context around a single, specific subject so that we could
easily compare the model’s responses before and after implementing RAG.
That said, there are some good next steps you could take to level up your understanding:
Consider using high-quality data and embedding models for better RAG performance.
Evaluate the model you use by checking Vectara’s hallucination leaderboard and consider using their model
instead. The quality of the model is essential, and referencing the
leaderboard can help you avoid models known to hallucinate more often
than others.
Try refining your retriever and generator to improve results.
My previous articles on LLM concepts and summarizing chat conversations
are also available to help provide even more context about the
components we worked with in this article and how they are used to
produce high-quality responses.






















{kind=link}