Google selecting the wrong canonical URLs? Here’s how to fix “Duplicate without user-selected canonical” errors and prevent indexing issues.
The first time I saw the “Duplicate without user-selected canonical” error in Google Search Console, I gulped. “Oh, no. Please, not this.”
Then I saw it again – and again. I heard rumors of other SEO professionals experiencing the same error.
I hope it was just another bug in Google Search Console. “It can’t be. It has to be a joke,” I thought.
It was snowballing, and it felt like there was nothing I could do to stop it.
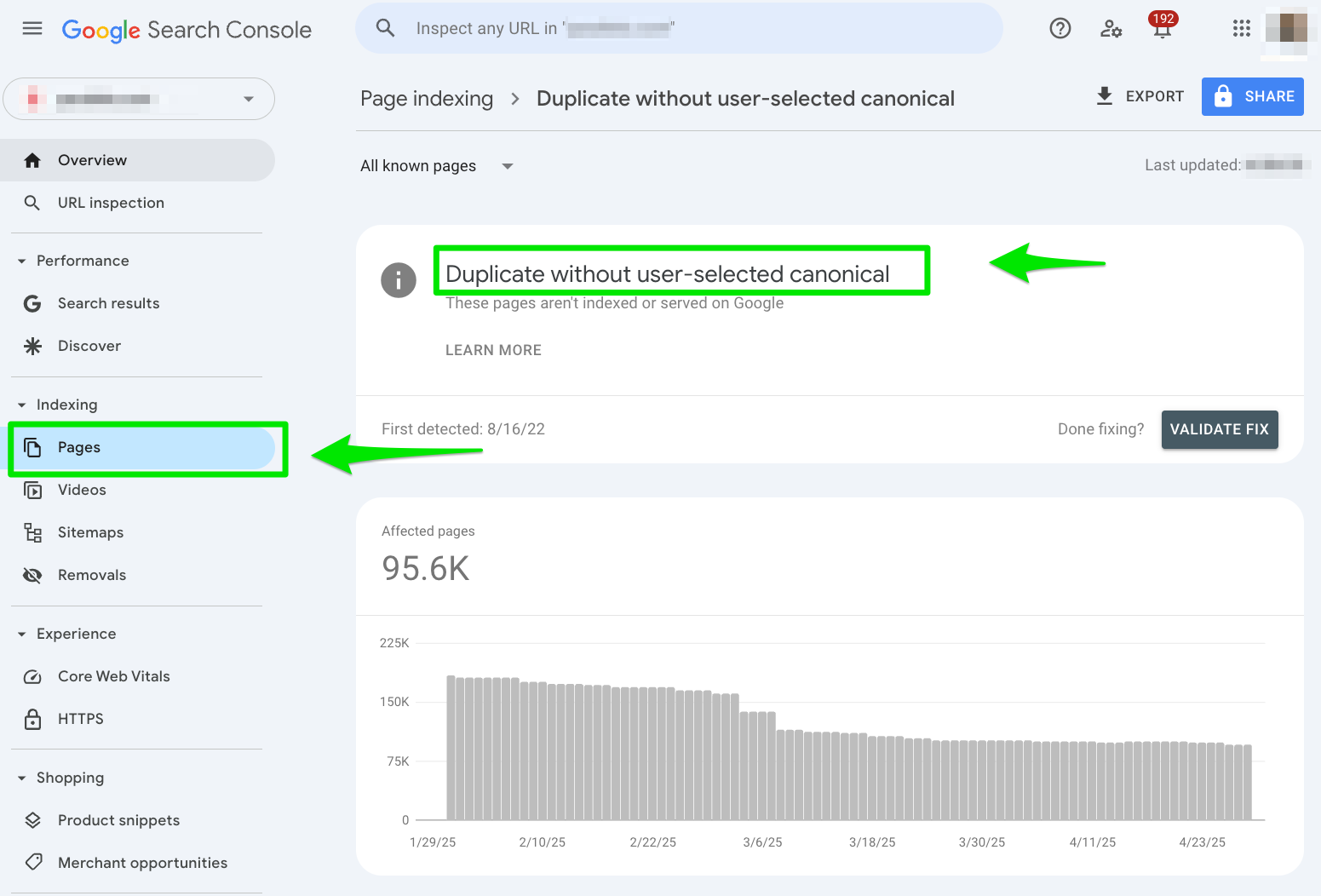
It’s one of the worst Google Search Console errors to hit the streets, and it’s more charitable than the chunky sneaker fashion craze.
It’s time for us to band together and figure out a way to fix these Google Search Console errors.
How do I fix a ‘Duplicate without user-selected canonical’ error in Google Search Console?
1. Go to Google Search Console > Pages > Duplicate without user-selected canonical
Head over to Google Search Console’s Pages report and select the “Duplicate without user-selected canonical” error under the Why pages aren’t indexed section.

Once you’re in there, export the report into a spreadsheet.

2. Check your canonical tags
Next, manually check your canonical tags for a sample size of the URLs from the report. I manually check around 10 URLs with the Inspect URL tool in Google Search Console.
If you notice a pattern where Google selects your canonical tag, you should implement self-referencing canonical tags sitewide.
In the example below, you can see that this URL is missing the user-declared canonical tag. Google is selecting its own canonical tag.

In your spreadsheet, you can begin to filter by common duplicate content issues that can be fixed with proper canonical tags, like:
- Parameter URLs: Anything after the
?should have a self-referencing canonical tag. - Language subfolders: Double-check your language subfolders (e.g.,
/en/).
2. HTTP vs. HTTPS
Another common reason this error appears in Google Search Console is the incorrect redirect error from HTTP to HTTPS.
HTTP is like watching a VHS movie, while HTTPS is like watching the same film in 4K streaming.
Google prefers the HTTPS version of your site.
For example:
https://website.com/https://website.com/
And Gary Illyes of Google confirmed it, saying:
“DYK that HTTPS URLS in a dup cluster have a higher chance of becoming canonical?”
So if you see your HTTP version still hanging around in your export spreadsheet from Google Search Console, you’re diluting your own content.
I recommend using a 301 redirect from HTTP to HTTPS.
If you can’t do that, add a canonical tag to every HTTP variant.
3. Include a trailing slash in URLs
If you want to play it safe, always include a trailing slash in your URL to avoid duplicate content.
The key is consistency.
John Mueller from Google breaks it down:
- “The slash after a hostname or domain name is irrelevant… but a slash anywhere else is a significant part of the URL and will change the URL if it’s there or not.”
Translation: Don’t skip that slash. Dropping or adding it changes your URL and can create duplicate content.
For example:
https://website.com/double-decker-tacohttps://website.com/double-decker-taco/
Google treats both URLs as separate pages.
Once you have your URLs with the trailing slash set up, create a 301 redirect from all the URLs without the trailing slash.
4. www vs. non-www
Picture this: you send out two versions of the same dish, one plated on fine china and the other in a Chinese takeout food box. They have the same recipe and flavor.
But to Google, they’re two entirely different entrées.
That’s how search engines see your www and non-www versions of your URLs.
For example:
https://www.tacosareawesome.com/https://tacosareawesome.com/
When it comes to choosing www or non-www versions, there’s no one side that is better.
Again, you just want to be consistent with your URL structure. Do not have both.
Whichever side you choose, remember to 301 redirect any URLs from your non-preferred version.
5. Session IDs or tracking parameters
Session IDs and tracking parameters are like serving loaded nachos with different toppings every time.
One with cilantro. Another with spicy sauce.
And another with a drizzle of lime.
The nachos are the same, but different.
Search engines treat your URLs with session IDs or tracking parameters as individual, separate URLs, causing duplicate content if not handled properly.
For example:
https://www.tacosareawesome.com/https://www.tacosareawesome.com/?utm=medium=referral/
The best way to handle URLs with parameters or session IDs is to:
- Do not include the parameter URL in internal links.
- Always include a self-referencing canonical tag without the parameters.
- Set up robots.txt files to block URL parameters.
User-agent: *
Disallow: /*?sessionid=
Disallow: /*?utm_source=6. Write original content
Google won’t penalize you for duplicate content, but it will filter out your weaker, similar, or repetitive pages.
That means your shiny new page might never see the light of day.
Ask yourself: Are you using the same intro or FAQ across your product or location pages?
That’s like wearing the same outfit to every party. You blend into the crowd.
I always aim to ensure each piece of content is 50% unique on each page, with a focus on the product description or regional information.
If you’re content is templated, search engines are likely yawning and ready for a nap after crawling your site. You want to keep your content fresh with a different angle.
Removing duplicate content is the only way to fix the ‘Duplicate without user-selected canonical’ error
Ah, the ancient art of fixing duplicate content is nothing new to the SEO industry. Every SEO professional has dabbled in it from time to time.
If you’ve got the “Duplicate without user-selected canonical” error in Google Search Console, I implore you to start auditing your content.
Because here’s the thing: duplicate content has never been cool. It was a spammy way to get rankings back in the day.
Remember that time when Who Let the Dogs Out was on every radio station? And Fubu was still around?
That’s when duplicate content was cool. Duplicate content will forever be a stain on the history of SEO.
Enough time will never pass for these errors to go away unless you roll up your sleeves and remove the duplicate content.
No comments:
Post a Comment