Overview
The
World Health Organization (WHO) reports suggest that the two main
routes of transmission of the COVID-19 virus are respiratory droplets
and physical contact. Respiratory droplets are generated when an
infected person coughs or sneezes. Any person in close contact (within 1
m) with someone who has respiratory symptoms (coughing, sneezing) is at
risk of being exposed to potentially infective respiratory droplets.
Droplets may also land on surfaces where the virus could remain viable;
thus, the immediate environment of an infected individual can serve as a
source of transmission (contact transmission). Wearing a medical mask
is one of the prevention measures that can limit the spread of certain
respiratory viral diseases, including COVID-19. In this study, medical
masks are defined as surgical or procedure masks that are flat or
pleated (some are shaped like cups); they are affixed to the head with
straps. They are tested for balanced high filtration, adequate
breathability and optionally, fluid penetration resistance. The study
analyses a set of video streams/images to identify people who are
compliant with the government rule of wearing medical masks. This could
help the government to take appropriate action against people who are
non-compliant.
Objective
Approach
Train Deep learning model (MobileNetV2)
Apply mask detector over images / live video stream
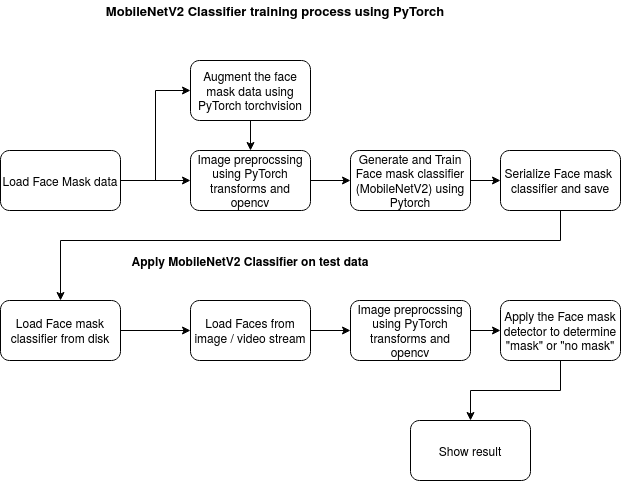
Data At Source
The raw images used for the current study were downloaded from PyImageSearch article and the majority of the images were augmented by OpenCV. The set of images were already labeled “mask” and “no mask”. The images that were present were of different sizes and resolutions, probably extracted from different sources or from machines (cameras) of different resolutions.
Data Preprocessing
Preprocessing steps as mentioned below was applied to all the raw input images to convert them into clean versions, which could be fed to a neural network machine learning model.
- Resizing the input image (256 x 256)
- Applying the color filtering (RGB) over the channels (Our model MobileNetV2 supports 2D 3 channel image )
- Scaling / Normalizing images using the standard mean of PyTorch build in weights
- Center cropping the image with the pixel value of 224x224x3
- Finally Converting them into tensors (Similar to NumPy array)
Deep Learning Frameworks
To implement this deep learning network we have the following options.
TensorFlow
Keras
PyTorch
Caffee
MxNet
Microsoft Cognitive ToolKit
We are using the PyTorch because it runs on Python, which means that anyone with a basic understanding of Python can get started on building their deep learning models.and also it has the following advantage compared with TensorFlow 1. Data Parallelism 2. It looks like a Framework.
- PyTorch DataLoader - which is used to load the data from the Image Folder
- PyTorch DataSets ImageFolder - which is used to locate the image sources and also have a predefined module to label the target variable
- Pytorch Transforms - helped to apply the preprocessing steps over the source image while reading from the source folder
- PyTorch Device - identifies the running system capabilities like CPU or GPU power to train the model. It will help us to switch the system usage
- Pytorch TorchVision - it will help us to load the libraries which are created before. Like pre-trained models, image sources and so on. It is one of core in PyTorch
- PyTorch nn - it is one of the core modules. This module helps us to build our own Deep Neural Network (DNN) models. It has all the libraries needed to build the model. Like Linear layer, Convolution layer with 1D, conv2d, conv3d, sequence, CrossEntropy Loss (loss function), Softmax, ReLu and so on.
- PyTorch Optim - help us to define the model optimizer. it will help the model to learn the data well. For example Adam, SDG and so on
- Pytorch PIL - helps to load the image from the source
- PyTorch AutoGrad
- another important module, it provides automatic differentiation for
all operations on Tensors. For example, a single line of code
.backward() to calculate the gradients automatically. This is very
useful while implementing the backpropagation in DNN
Image Classification Algorithm from PyTorch
MobileNetV2
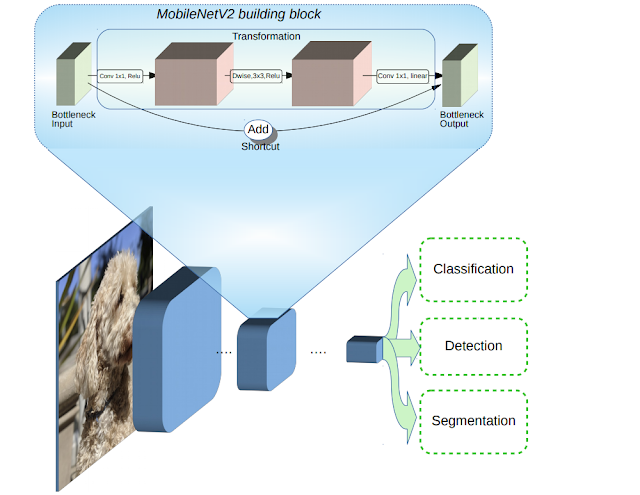
MobileNetV2 Architecture
The weights of each layer in the model are predefined based on the ImageNet dataset. The weights indicate the padding, strides, kernel size, input channels and output channels.
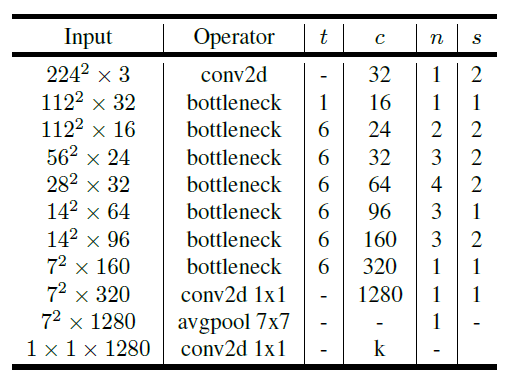
Why choose MobileNetV2?
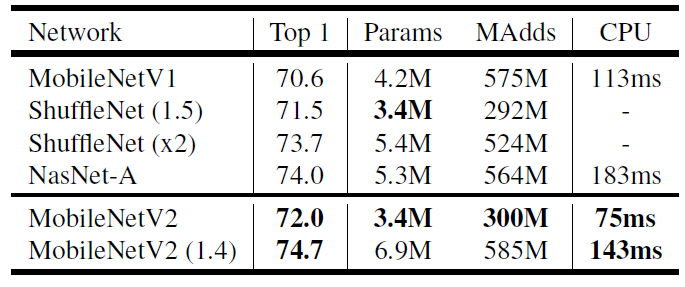
Image: Performance over ImageNet dataset
Face Mask Detector
Training with Face Mask
As described above I have used the augmented data which is a smaller dataset. I have also applied all the necessary preprocessing requisites applied on the top of source images using the PyTorch transforms, PIL and DataSets.
The sample face mask training files look like as below.

Image 1 . training set example
Model Overwritten
MobileNetV2 was chosen as an algorithm to build a model that could be deployed on a mobile device. A customized fully connected layer which contains four sequential layers on top of the MobileNetV2 model was developed. The layers are
Average Pooling layer with 7x7 weights
Linear layer with ReLu activation function
Dropout Layer
Linear layer with Softmax activation function with the result of 2 values.
The final layer softmax function gives the result of two probabilities each one represents the classification of “mask” or “not mask”.

Accuracy Overview

Image 2: Training vs Validation Accuracy
Test Sample
For the reference I have attached a single image prediction result.

Image: Test result
Face Mask Detection in Webcam stream
To identify the faces in the webcam
Classify the faces based on the mask.
Identify the Face in the Webcam
To identify the faces a pre-trained model provided by the OpenCV framework was used. The pre-trained model is based on Single-Shot-Multibox Detector (SSD) and employs a ResNet-10 Architecture as the backbone. The model was trained using web images. OpenCV provides 2 models for this face detector:
Floating-point 16 version of the original Caffe implementation.
8 bit quantized version using Tensorflow.
In this example I have used the Caffe model in this face mask detector.
SSD Basic Architecture

Single-shot MultiBox Detector is a one-stage object detection algorithm. This means that, in contrast to two-stage models, SSDs do not need initial object proposals generation step. This makes it, usually, faster and more efficient. This model will return the array of faces detected on the video frame.
Face Mask classifier
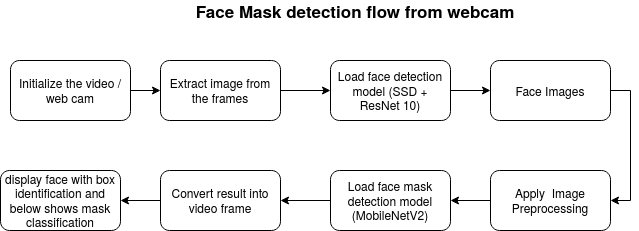
Face Mask identification on Stream
The live stream test video is ,
Conclusion
The
current study used OpenCV, Pytorch and CNN to detect whether people
were wearing face masks or not. The models were tested with images and
real-time video streams. Even though the accuracy of the model is around
70%, the optimization of the model is a continuous process and we are
building a highly accurate solution by tuning the hyper parameters.
MobileNetV2 was used to build the mobile version of the same. This
specific model could be used as a use case for edge analytics.
No comments:
Post a Comment